
The "Roger-Ebertron": Modeling Roger Ebert's Movie Ratings
The “Roger-Ebertron v0.3” is my machine learning algorithm designed to learn how renowned late movie critic Roger Ebert would review movies today.
This is Project 2 at Metis Data science. Codenamed Luther, our goal is to use web scraping, linear regression, and supervised machine learning techniques to look at an interesting question related to movie and film.
With the abundance of data on movies, scripts, reviews, and forums for everyone - critics and general audience to express their opinion on movies - can I try to model Mr. Ebert’s movie ratings against everyone else’s?
This is v0.3 because my first two attempts looked at different questions about movies. As Liv Buli said to Metis students, sometimes your data just doesn’t tell a compelling story. You can read about my initial attempts in an upcoming blog post.
Outline
- Introduction
- Question
- Data
- Challenges and Assumption
- EDA & Feature Selection
- Regression
- Testing
- Prediction
- Conclusion
- Next Steps
- Code
Question
Today, Netflix and Amazon can accurately and, most of the time, satisfactorily recommend movies or products that we would enjoy - based on our past viewing preferences, ratings, or purchases.
So I would like to explore the question: Can we model the movie preferences of the late Mr. Roger Ebert and estimate how he would continue to rate movies today?
Furthermore, can we create a machine learning algorithm that can not only rate movies similarly, but maybe even analyze movie elements and write reviews as he had?
Data
- Scraped www.rogerebert.com for 4,494 movie reviews spanning the last 24 years of Mr. Ebert’s prolific career.
- OMDb API flat file containing movie metadata and review ratings from IMDB, Metacritic, and Rotten Tomatoes as of Jan. 1, 2016.
Challenges and Assumptions
Mr. Ebert do not review movies like most people. certainly not me.
He understands movies. He looks at theme, cinematography, good acting, good direction, and plot. So then, how can we accurately predict his rating?
 Roger Ebert and his famous “thumbs up” pose
Roger Ebert and his famous “thumbs up” pose
My goal for this project is to see if we can use the reviews and ratings of the masses - general audience and critics - to create a model of Mr. Ebert’s ratings to see where he might agree and where he would deviate from everyone else.
Sometimes ratings are considered a rank (e.g. Top 10 best movies based on ratings), which may be difficult to predict with linear regression. However, I assume that rating is in fact a continuous quantitative interval.
EDA and Feature Selection
First, I perform some exploratory data analysis to get an idea of my features and my target. It’s simple to plot a histogram of Mr. Ebert’s movie ratings.
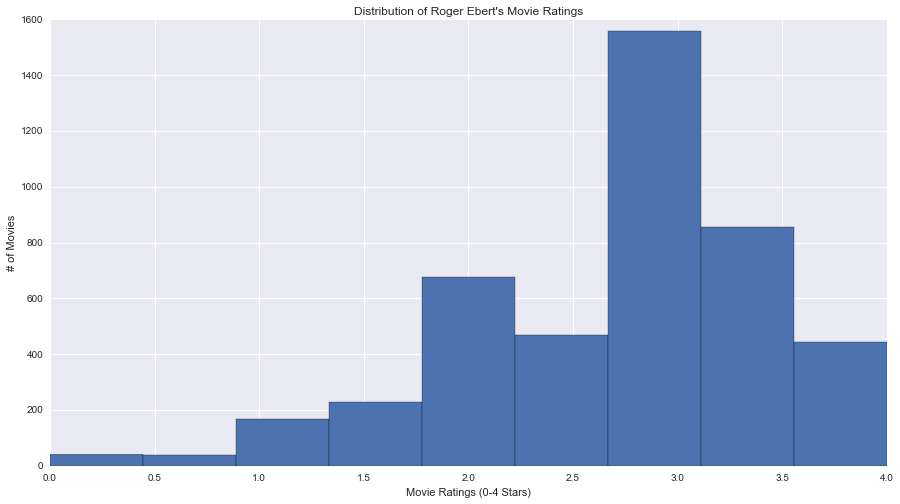 Historgram of Roger Ebert’s movie review ratings since 1994
Historgram of Roger Ebert’s movie review ratings since 1994
In the histogram each of 9 bins corresponds to one of the possible ratings that Ebert gives in this 0 - 4 star ratings, with half stars allowed. We see a left or negatively skewed distribution.
It looks like he has given out almost twice as much 3 star ratings than any other. And more than half of his reviews are above a 3 stars. (Indeed, Ebert had addressed this specifically in this article that explains how he rates his movies.)
On the left side, we see very few movies that have the terrible rating of 0 and 0.5
Pair Plot and comparison with other ratings
Let’s examine his ratings in comparison with other critics and movie audiences with a pair plot looking at movie ratings from Metacritic, IMDB, and Rotten Tomato’s User and Critic rating.
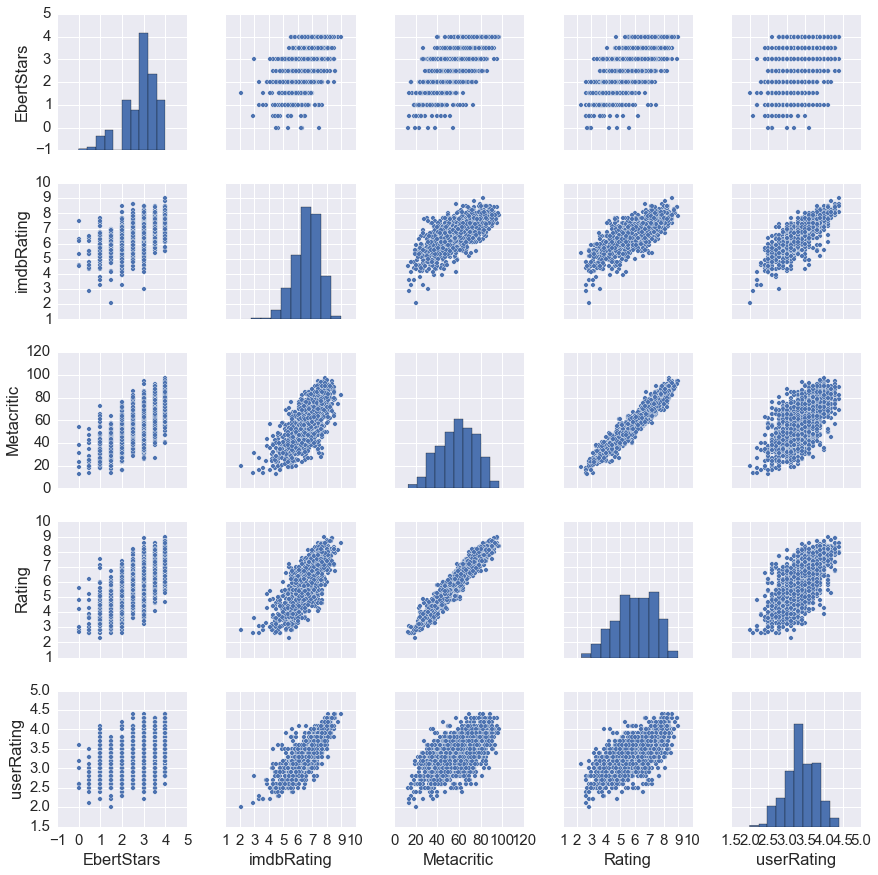
Looking across the first row (or down the first column, same thing), we see that there is some correlation between Ebert’s ratings with other rating metrics. And looking at how other ratings relate with one another, we see it tends to follow in a good linear relationship.
Let’s take a closer look at Ebert’s ratings vs. IMDB’s:
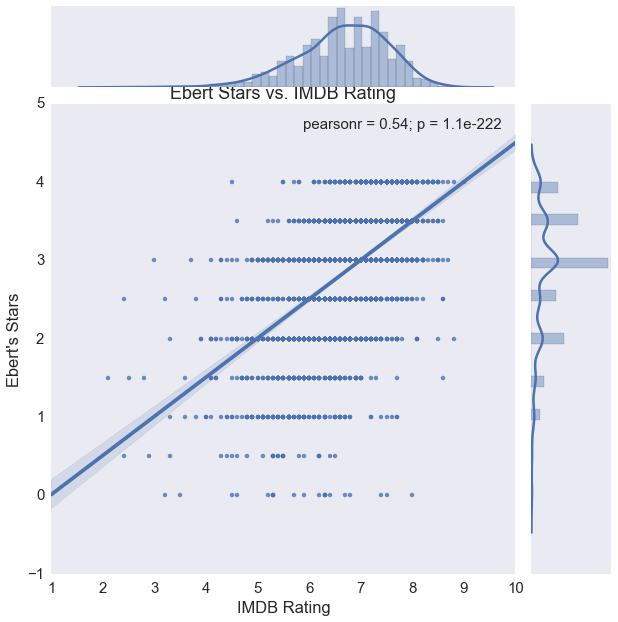 Scatter plot of Ebert’s ratings vs IMDB with an OLS regression line
Scatter plot of Ebert’s ratings vs IMDB with an OLS regression line
Notice how IMDB’s ratings are also left skewed. Between the two ratings, we have a good positive relationship with a Pearson’s correlation of 0.54. What about with Metacritic?
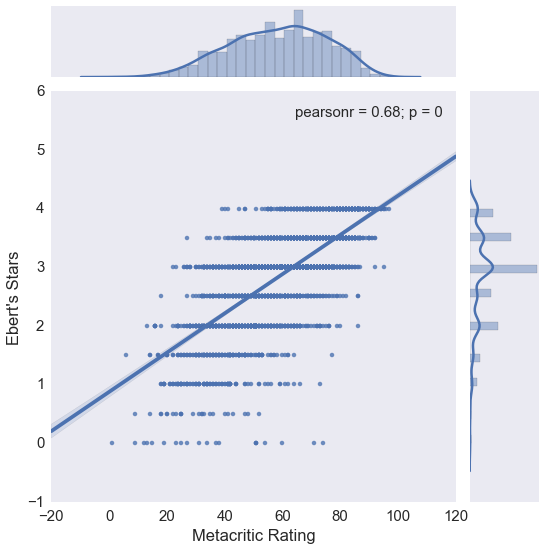 Scatter plot of Ebert’s ratings vs Metacritic scores with an OLS regression line
Scatter plot of Ebert’s ratings vs Metacritic scores with an OLS regression line
Pearson’s correlations is higher this time: 0.68.
Indeed, Rotten Tomatoes ratings are also positively correlated with Ebert’s ratings. Here’s its relationsip with Critic and User’s ratings:
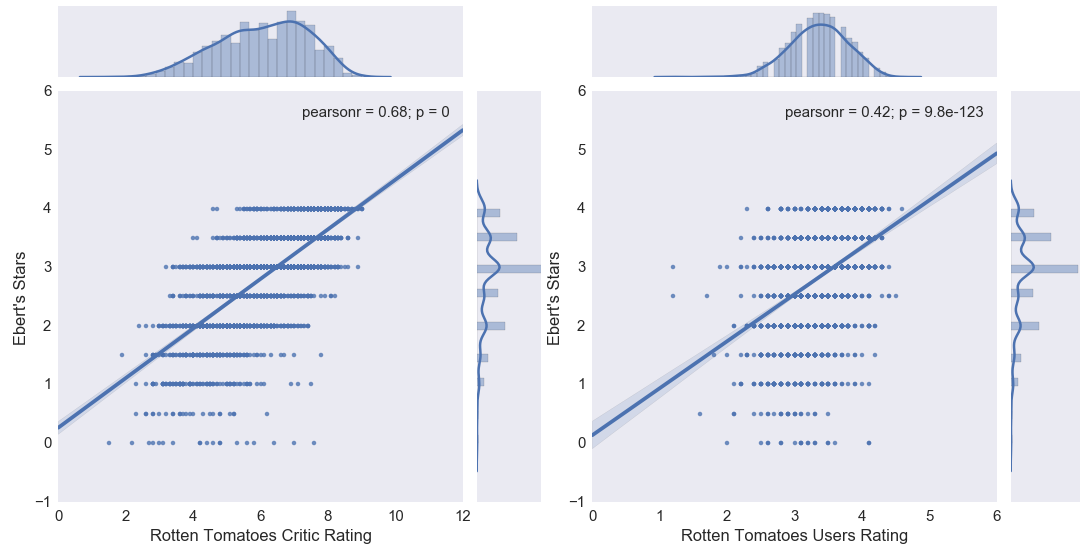 Scatter plot of Ebert’s ratings vs Rotten Tomatoes Critic and User review ratings.
Scatter plot of Ebert’s ratings vs Rotten Tomatoes Critic and User review ratings.
Pearson correlation shows a 0.68 and 0.42, indicating that there’s a stronger correlation with critics’ than users’ ratings.
Genre distribution
Are genres important to Ebert to his review of the movie? Or maybe it’s the other way around; dramas tend to emphasize on plot and storytelling than say comedy or horror films. Let’s look at Mr. Ebert’s distribution across the 23 genres that he has identified in his reviews:
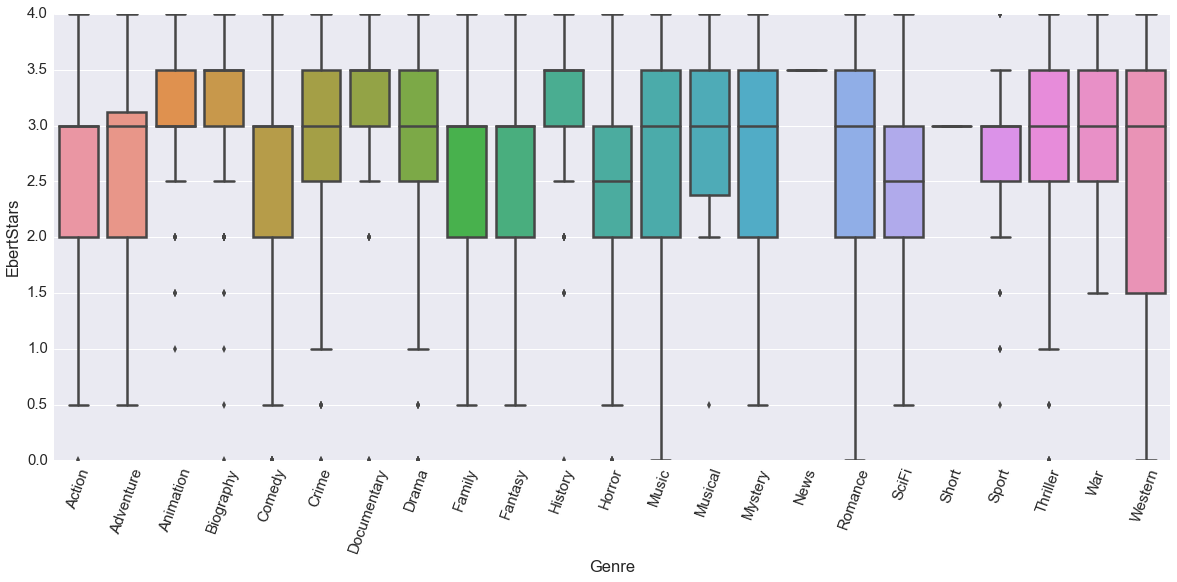 Boxplot of movies ratings by Mr. Ebert grouped by their movie genres.
Boxplot of movies ratings by Mr. Ebert grouped by their movie genres.
This box plot shows the distribution of the 1st to 3rd quartiles in the colored box with the line in the middle as the median. This whiskers indicate the complete range of reviews, but any outliers are just dots. Outliers are determined by any significant difference from the IQR (colored box).
One interpretation of the box plot can say that while most genres do run the gamut of ratings (as seen from the range of the whiskers), some genres are consistently rated better. See the higher position of the boxes for animation and documentaries compared to horror or sports.
This clear distinction means that we will consider genre as an important factor. To incorporate a categorical feature like genre, we will construct dummy variables for each genre. An animated family fantasy like How to Train Your Dragon will have a 1 under each of those genre’s column in our model, and 0 for genres of which the movie is not.
Linear Regression
Now that I’ve done some feature engineering, I begin modeling with linear regression.
1. Regression With just ratings
First, what does the model look like if we just use the various ratings as
features?
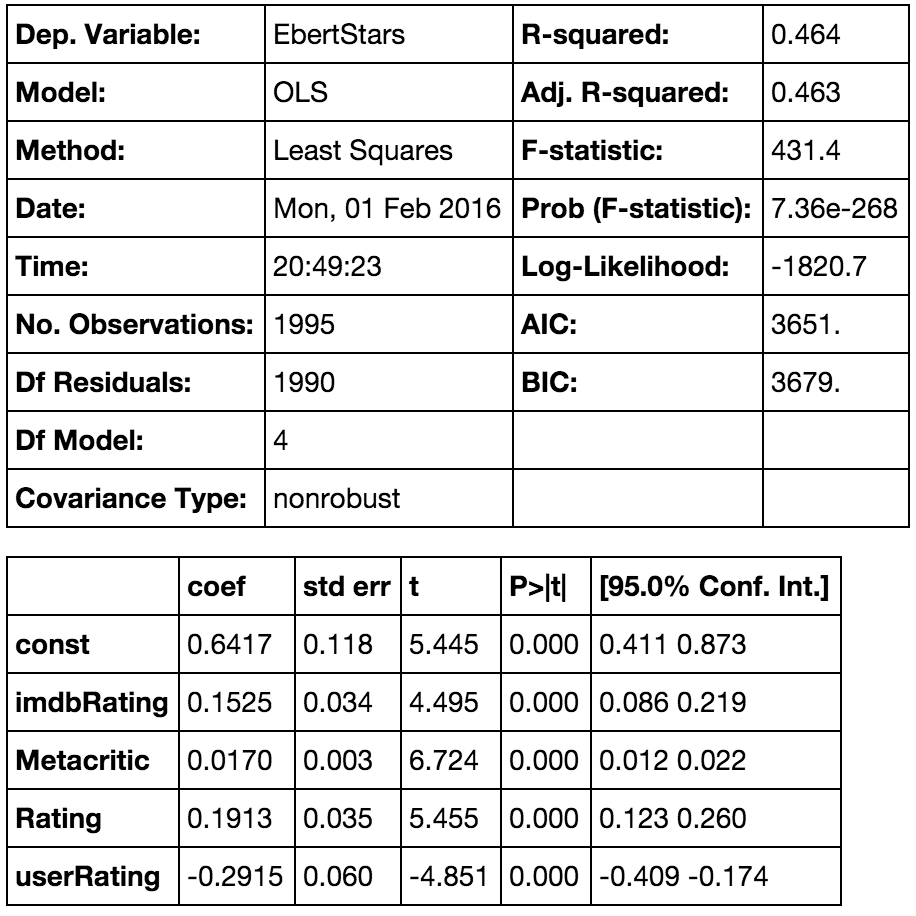
Our results show a decent R-squared of 0.464. The F-statistic, or Probability is almost zero, meaning that it is unlikely for this model’s results to have by chance.
Our coefficients are cool too. It’s saying that Ebert would agree with IMDB and RT’s critic score, but disagree with RT’s user ratings.
2. With genre
Now, when I include the dummy variables for genre in the linear regression, I obtained a vastly improved R-squared of 0.960.
This is good, but we want to be sure that this model is accurate. But to be sure, we should use cross-validation to see if our model’s result is consistent.
3. Cross Validation
So here I use Scikit Learn’s cross validation and linear regression package.
regr = linear_model.LinearRegression()
scores = cross_val_score(regr, X_2, y_train, cv = 5)
print scores
print scores.mean()
>>> [ 0.45167339 0.46498555 0.50503508 0.43065667 0.47263781]
>>> 0.464997701221
My measure of error here - mean absolute error is between 0.45-0.50 stars. Half a star of difference in our predicted rating.
Testing on Test Case
Now we’re confident with a regression model on our training data, we apply it to the test set.
MAE: 0.434381067311
MSE: 16.462922295
Looks like on the test case, our model’s accuracy is pretty consistent. This is a good sign.
Predicting Recent Movies
With our model ready, I apply it to a few new movies in the beginning of 2016. I look at Star Wars: Episode VII - The Force Awakens and Dirty Grandpa by finding their current ratings on various sites, and transform their genre to boolean.
starwars = np.array([93, 8.4, 9.2,9.0,1,1,0,0,0,0,0,0,0,1,0,0,0,0,0,0,0,1,0,0,0,0,0,0])
dirtygrandpa = [18 , 5.8, .8, 5.2,0,0,0,0,1,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0]
print 'Star Wars:', model2_fit.predict(starwars)
print 'Dirty Grandpa:', model2_fit.predict(dirtygrandpa)
>>> Star Wars VII: 3.36349643
>>> Dirty Grandpa: 0.52286363
The regression model suggests that Ebert would give Star Wars between 3 and 3.5 stars. On the other hand, Ebert agrees with most critics that Dirty Grandpa, is not a great movie. 0.5 stars.
Conclusion
In conclusion, I am able to build a linear regression model that can predict Roger Ebert’s movie ratings within 0.5 stars by using reviews by today’s film critic and general movie audience.
Next Steps
So far I’ve been able to accurately model Roger Ebert’s reviews based on other reviews and the movie’s genre. But we can always add more features like a movie’s budget and production. Or also consider actors, directors, and cinematographer to our model.
Possible extensions here may be using NLP and clustering to understand how he writes his reviews and what film elements he looked for. Then we can analyze a movie’s script or text of other reviews to see if they align with
Code
You can find my Python code at Github repository, documenting my process to scrape web data, cleaning it, and the regression models.
-->